扫描二维码
关注北京大学汇丰金融研究院官方微信/微博

北京大学汇丰商学院管理学教授、商业模式研究中心主任、中国企业信息中心主任,“魏朱商业模式理论”创始人魏炜及其合作者以ChatGPT为标志的人工智能为切入点,于《北大金融评论》撰文探讨大模型时代下企业商业模式的选择和判断,分析OpenAI模式的局限性,并针对这些局限性提出未来可能的发展方向,即依托“生成式大模型+辨识型小模型”技术架构形成领域大模型,并由此提出领域大模型的商业模式选择。
文章将刊登于《北大金融评论》第16期。

凯文·凯利在其撰写的《5000天后的世界》一书的开篇中就写到:“在未来的50年里,AI将成为可以与自动化和产业革命相提并论的,不,应该是影响更为深远的趋势。”按照凯文凯利的判断,未来的这个世界被称为“镜像世界”,在这个世界里,将会诞生“新的巨大平台”。他总结归纳得出如下判断:互联网作为第一大平台,将全世界的信息数字化;社交媒体作为第二大平台,解决了人际关系数字化;继两大平台之后,第三大平台也即将全新登场,即镜像世界,将现实世界全部数字化。
我们认同这一判断,也相信人类正在快速地进入AI世界,并因此更加深入去理解以ChatGPT为标志的人工智能带来的一系列的挑战和机遇。在此时此刻,企业和从业者的兴奋和焦虑、期待和失望、绝望和希望同时并存。如何在大模型时代抓住商业机会,构建独特的商业模式使其在大模型浪潮下依旧能披荆斩棘,是每个企业当下都需要思考的重要命题。
正如我们在开篇讨论的那样,随着ChatGPT的横空出世,人们或者因为敏感其带来的机会,或者因为焦虑其带来的颠覆,都在想办法让自己与其发生关联。但是,这是一个从0到1的过程,进入的路径非常多,同时坑也特别多。和之前发生的数字技术背景下生存的芯片、操作系统等领域不一样的地方是,现在没有时间的壁垒,先发者也不会形成累积性的竞争优势,正因为此,其对产业的颠覆也将超乎人们的想象。
在这样的变化特征下,大模型时代的商业模式,需要针对这样的变化特征做出应对,并利用这些变化特征产生新的商业价值机会,因此,需要在现在生成模型的基础上,解决行业知识与时间价值的问题,后者我们发现可以用行业辨识型模型来解决,即必须使用辨识模型来解决生成模型的不足。辨识模型补足的是两个比较重要的方面,一个是业务场景中特有的需求,另一个是结构化知识的生产,类似人类形成长期记忆。长期来讲,两者一定是缺一不可的。
从企业的视角去看,有关企业商业模式的构建,可以确定是一个领域大模型,这一大模型主要由小模型(辨识模型)产生的专业知识图谱、提供通用知识和语言理解与组织能力的大模型(生成模型)两部分组成。小模型的主要功能是基于知识图谱等技术,为大模型提供训练和微调的专业知识,以便生成式大模型进行专业知识的理解。
通用大模型的主要任务是面向客户直接进行语义理解和答案的生成,如闭源的ChatGPT、开源的LLaMA等均属于此类通用模型。我们可以简单介绍一下构建这样一个领域大模型的过程。
第一步是训练基于生成式大模型的自然语言处理模型,其训练主要分为预训练和迭代微调两个步骤。步骤一,预训练阶段,利用海量语料训练生成式大模型,得到大模型的模型文件。步骤二,迭代微调阶段,依据指令提示学习和思维链提示学习对上一步的模型文件进行微调,再通过强化学习的方式,分别进行奖励模型训练和生成策略优化。
第二步是用辨识型小模型生成领域知识图谱。小模型部分本身也是一个针对特定任务的自然语言处理模型,其训练同样分为预训练和微调两个步骤。步骤一,预训练阶段,可以采用BERT、T5等预训练模型。步骤二,微调阶段,利用各种针对不同下游任务的语料对预训练的模型进行特定领域的微调。利用微调后的自然语言处理模型,可以基于语义理解方面的能力,生成特定领域的专业知识图谱。
第三步,分析专业知识图谱,并进一步将从其中得到的专业信息用于大模型部分的增量预训练、微调、校验和溯源,产生具备专业知识能力的领域大模型。
第四步,利用加入了专业知识的领域大模型,实现专业领域的文本解析、报告生成和专业问答,同时也可以解决通用大模型在专业领域的非事实性回答的问题。
不同于行业某些专家认为“不要用知识图谱、它根本不起作用”的观点,我们通过开发实践证明知识图谱,在解决纯生成式大模型(如GPT4)关于事实性问题的缺陷方面不但能发挥关键作用,而且相比于生成式大模型+插件机制的架构(如Bing Chat),经过知识图谱微调、校验和溯源的领域大模型在事实准确率和生成内容的专业性方面有着非常突出的优势。
大模型的共生体和商业模式创新
领域大模型在未来拥有更加丰富的商业化场景,这些场景将形成一个如图1所示的大模型共生体。该共生体拥有以下角色和相应的业务活动环节,包括搭建训练框架、输出模型文件、模型微调、私有模型及其部署、开放API、构建知识图谱知识、构建终端应用和提供训练数据等。进入该共生体的企业可以通过选取不同的业务活动并在其中扮演特定的角色,与共生体中的其他主体交易,由此可以衍生出很多不同的商业模式。

商业模式创新的起点可以源于对共生体中不同角色的选择,这能够帮助企业定位其边界以及交易的主体。如下图2所示,这是一个大模型共生体的三轴工具。其中,Y轴代表了上下游直接业务活动,包括了搭建训练框架、预训练、输出模型文件和终端应用等。X轴是直接业务活动的横向展开,在不同的直接业务活动层面进一步区分出不同的活动。例如,训练框架、预训练数据可以选择是开源、闭源(私有)还是混合;在模型文件环节可以选择GPT-3、GPT-4、Stable Diffusion等不同的训练好的模型参数数据;在终端应用环节可以切入对话、搜索、画图、写作等多样化场景。除此以外,Z轴代表了业务活动的竖向分层。例如,针对提供模型文件这一业务活动,将已有训练好的模型参数数据当作基础模型,企业可以通过模型微调使用特定领域或任务相关的全量或增量语料,对模型进行进一步训练。在模型微调的基础上企业可以提供客户的私有模型部署,客户将系统的组件和服务部署在自己的私有数据中心或基础设施中,不仅满足了对数据隐私和安全性的要求,还可以进行定制开发以满足特定的业务需求。

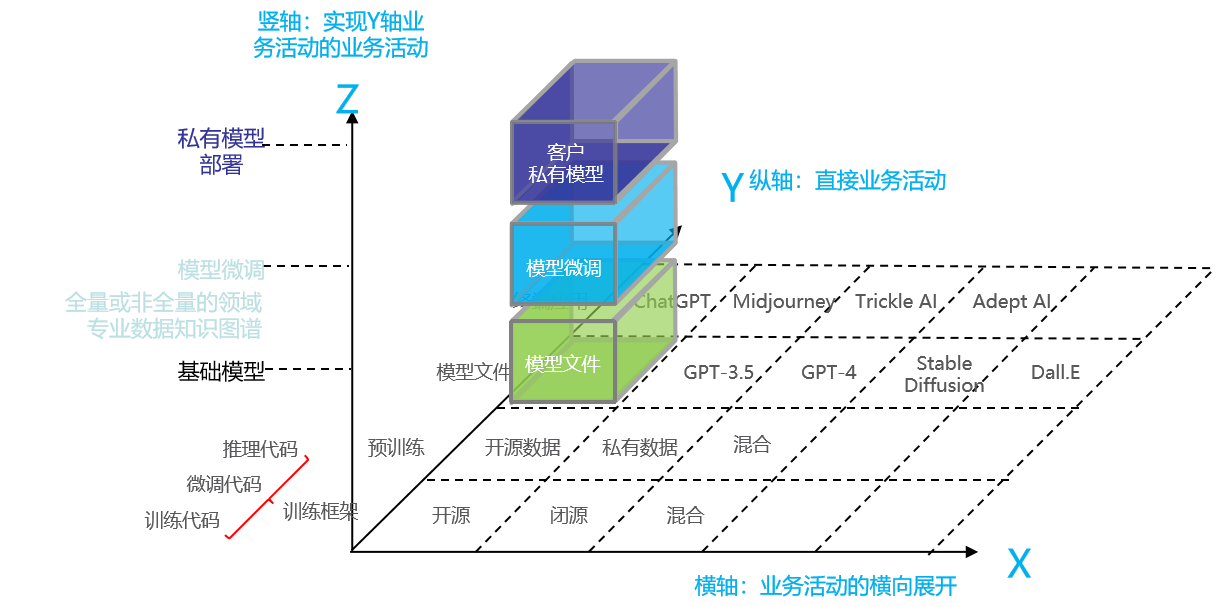
图2 大模型共生体的三轴工具
三个坐标轴充分表达了现有的业务活动。拥有不同初始禀赋、技术优势的企业可以从事共生体中不同的角色,从而采取不同的大模型的商业模式。例如:
模式1,通用大模型训练与提供模型文件的商业模式。企业的主要业务活动选择为基础的通用大模型训练,通过出租或销售通用大模型盈利。
模式2,企业自用领域大模型训练的商业模式。企业在自用场景下,对通用大模型的模型文件进行领域适应性的二次微调,输出一种满足专业企业需求的领域大模型。
模式3,为不同行业提供领域大模型文件的商业模式。企业可以结合领域专业数据公司提供的专业化数据构建领域知识图谱,训练更适用于垂直领域需要的领域大模型。
模式4,结合知识图谱的领域大模型训练的商业模式。这类企业的核心在于承担了知识图谱构建的活动,为某一领域构建更加专业化的解决方案。
模式5,平台型商业模式。这类企业将模型训练的基础设施开放给用户,让用户开发属于自己的领域大模型。
模式6,一体化且可私有化部署的商业模式。企业提供领域大模型或通用大模型,可提供模型文件给用户私有化部署。此模式与现行的OpenAI的API模式相比,能够激励行业客户创造专属的领域大模型。
这个路径的选择是普遍可应用的吗?
我们确定“生成式大模型+辨识型小模型”作为大模型时代企业的技术架构及大模型的商业模式选择路径,
友情链接:
联系我们:
扫描二维码
关注北京大学汇丰金融研究院官方微信/微博
 微信公众号
微信公众号 微博
微博
© 2018版权属北大汇丰商学院所有
ICP备案编号:粤ICP备12081285号